


Evolution of Barcodes: Beyond Barcodes
In this final part of the Evolution of Barcodes series, we will take a look at the future of barcode technology, including alternatives in automatic identification and data capture (AIDC). In general, technology is rapidly improving throughout society, while inventors and engineers everywhere are trying to define the next step in the barcode’s evolution. This article will consider many such possibilities, with only time telling what’s in store for barcoding technology.
Today, consumer barcodes are most easily found in the supermarket, in the form of UPC, EAN, and Databar barcodes. The mass of products located in supermarkets makes it nearly impossible to not find an item without a barcode. Barcodes are most frequently used to identify objects, making them perfect for the mass cataloging and identification that takes place there. The same holds true for inventory control applications, warehousing, logistics, and so on, where Data Matrix and Code 128 symbologies are most frequently used. But couldn't this same solution of simple and quick identification of items be solved in other ways? What concerns are being addressed about damages, performance, printing expense, security, and fraud prevention? Is this can of Coke really produced by Coca-Cola? That’s exactly the question that researchers and inventors are asking themselves while pushing barcode technology forward.
Barcodes or Branding?
Traditional black-and-white stripped barcodes offer an effective machine-readable data format. The “code” stored is simply an identifying message of the product that a barcode system recognizes and treats accordingly: for example, looking up the price, quantity, and size of the item for a consumer packaged good (CPG). As reliable and entrenched as these types of barcodes are, they have some weaknesses:
- At a point of sale (POS) system, the cashier must locate the barcode on the package and orient it accordingly for a successful scan.
- There is minimal error protection and redundancy: while product barcodes do employ checksums and use self-checking encoding techniques, they still offer limited protection for even moderately damaged barcodes.
- Product manufacturers must always reserve space on their package for the product label, which has minimum size and placement requirements. Label space is often at a premium, especially on smaller products.
Enter Digimarc. Digimarc integrates semi-transparent watermarks within the product’s normal package labeling. Instead of having a single fixed barcode on the package, the virtually invisible Digimarc watermark is usually repeated many times over the entire product packaging. No black and white stripes to find; just wave the item in front of the specialized POS scanner, and the machine recognizes the product simply by its watermark.
How is this an improvement? It makes scanning drastically simpler. It doesn't require the cashier or the consumer to search the package for a barcode: all that is done is a wave in front of the POS scanner. This increases the speed of checkout and allows the cashier to focus on the guest, improving customer service. An additional benefit is that it ignores a damaged barcode: unless the entire label is ruined, or completely removed, the scanner will be able to recognize the product. This reduces the number of items unable to be sold due to damaged barcodes and undoubtedly lowers customer frustration.
In the words of the Chief Technology Officer of Digimarc, Tony Rodriguez, “Digimarc is uniquely positioned to change the landscape of consumers’ shopping experiences. The Digimarc Barcode can do everything that a traditional barcode does today but better, and it can be added to many things that can’t be barcoded today. Simply put, we’re the barcode of everything.”
RFID
While replacements for barcodes might not become quite as useful in your average grocery store, they do more efficiently solve other problems barcodes don’t perfectly solve. RFID, which stands for “Radio-Frequency Identification,” is similar to a barcode in that an RFID tag stores information that the reader can ‘read’ from over a large distance. This long-distance readability makes it an excellent tool for anywhere where long-distance communication of information is important, such as warehouse, vehicle, or animal tracking.
RFID tags all have a similar design: within the tag, there is a small antenna, a microchip, and, in some cases, a battery. At the most basic level, these electronics work together in the following way:
The tag’s antenna receives an electromagnetic wave from the scanning device, which activates the tag’s components;
The tag then sends radio waves back to the scanning device, powered either by the tag’s internal battery or power gathered from the electromagnetic wave;
A receiver in the scanning device then picks up the radio waves and interprets the signal, gathering the information stored in the microchip.
There are three different types of RFID tags: active, semi-passive, and passive:
Active RFID tags are the most expensive types of RFID tags, but they also have the ability to transmit information farther than any other tag. This allows them to reach ranges beyond 300 feet, and even further when more power is put into the tag. The drawback, however, is that the tag actually needs power. This makes it more expensive and bulky compared to the other two tags, but it takes away the need for the reader to push power into the tag itself. These are the type of tags that could be found on railroad cars, or inside warehouses: any items that need to be read over a long distance. Some tollgates on major highways use RFID tags to allow people to drive under the reader; the reader reads the tag located in their vehicle, and a charge is applied to their account.
Semi-passive RFID tags are similar to active RFID tags in that they are powered by internal batteries. Semi-passive tags, however, rely somewhat on power provided by the signal from the scanner. This allows them to have more range than a passive RFID tag, but less range than a fully active RFID tag. Likewise, it is less bulky than an active tag, but, since it still has an internal power source, is bulkier and more expensive than a passive tag.
Fully passive tags are the smallest, cheapest, but weakest of the three main RFID tags. Their readability range is less than twenty feet but costs only between 7 and 20 cents to manufacture. This makes them ideal for mass-production and everyday usage scenarios.
RFID tags are superior to barcodes in several ways. Their main attribute is they don’t need to be visible to be read by the receiver. This allows them to be stored within the packaging, preventing them from being damaged. Another benefit of not needing to be visible is they don’t need to be manually scanned: the receiver will automatically gather information stored in the tag. This allows the whole “read” process to happen dramatically faster than the scanning of a barcode. An additional benefit over traditional barcodes is that the information stored on a tag is changeable. This is a strong improvement over barcodes, as it allows the tag to be reusable and updateable.
A drawback to the use of RFID tags is that they have security risks that are expensive to circumvent. Tags are difficult to encrypt, and radio technology isn't exactly difficult to obtain. It is possible to protect the tags against a process called “skimming”, which is scanning the tag without the owner’s knowledge or consent, but, when mass producing this protection for every RFID tag, the cost may quickly become prohibitive. RFID tags are already significantly more expensive than any barcode; reducing the cost of AIDC mechanisms is one of the most important goals of the industry. While RFID has the potential to be used everywhere in our lives, until researchers discover a way to cheaply and effectively protect the information stored on RFID tags, it is doubtful that RFID technology will move into the mainstream.
3D Barcodes: Moving into the Future
We are familiar with one-dimensional (1D) barcodes, the traditional type recognizable by their straight black lines, and two-dimensional (2D) barcodes, the newer model of barcodes characterized by their distinctive square shape. However, what happens if we expand barcodes into another dimension, and label objects in a three-dimensional (3D) space? We will now examine the different approaches to this 3D barcode design, its appeal to businesses and consumers, and the problems facing the technology.
Cubism in Barcodes?
The primary goal of all barcodes is to store information in an accessible and affordable manner while taking up as little space as possible. This is what many companies are attempting to achieve by creating 3D barcodes. However, many companies are taking different approaches as to what exactly a 3D barcode is. For example, a team at the National Physical Laboratory has created a 3D barcode that resembles a cube.
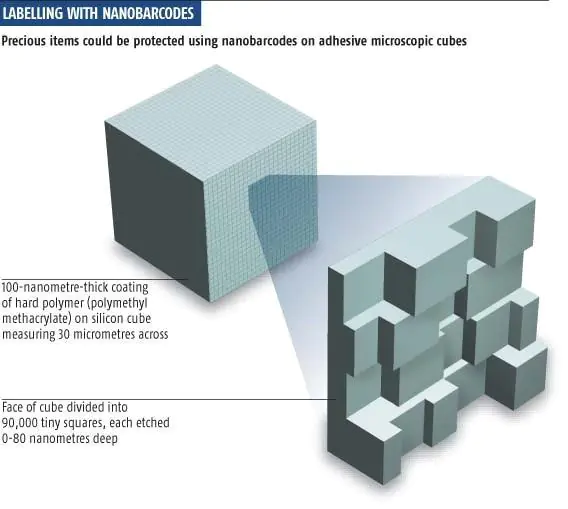
Known as Nanobarcodes, this cube is only 30 micrometers across; to put this size into perspective, this is three one-thousandths of a centimeter or roughly the length of a single skin cell. The cube is created using a device that drills 90,000 small squares into the cube, each with differing heights. These small squares at varying levels are what hold the information, similar to how the thickness of the black lines and the space between the lines on a 1D barcode represent the encoded information of the barcode. An automated microscope identifies these small squares; a process that takes around a minute.
While a single PDF417 symbol, using the lowest error correction level, can store up to 1850 text characters, 2710 numeric digits, or 1108 bytes of binary data, nano barcode storage is unbelievably more efficient. According to Alexandre Ceunat, a member of the team that created the technology, a cube has the potential to store “two copies of the bible, the King James version, on the sharp end of a pin.”
The storage capabilities of information in this cube design are very desirable to businesses, as it allows them to expand their creativity while not being limited by storage space. The team that created the cube, for example, also developed a highly advanced encryption system and coupled with the tiny size and the vast storage space of the cube, makes it ideal for protecting valuable objects from theft. Diamond merchants, art connoisseurs, and pharmacists have reportedly approached the team, hoping to protect their valuables. Even better, each cube would only cost slightly over a dollar, which is a small price to pay for the value it may protect.
However, cube technology does have its faults. Cubes are difficult to read due to their size and impossible to scan by any conventional means, such as a 1D or 2D barcode scanners. Realistically, the cube could never be used for labeling consumer products or posted in collateral. This limits its functionality outside of daily use, such as scanning items at a supermarket, marketing, or advertisement, and the way that many 1D and 2D barcodes are utilized. Additionally, each individual cube label is fairly expensive compared to conventional barcode printing. Standard barcodes are practically free, costing only the ink it takes to print.
While the cube is inexpensive for the protection it supplies, it is thousands of times more expensive than standard barcodes. These problems are, of course, just tradeoffs for the potent promise it holds over standard barcodes, holding exponentially more information in much smaller space. Given the right use case, efficiencies, and affordability, cube technology could certainly revolutionize the way barcodes are used and help advance AIDC as a whole.
Bigger, Better Barcodes
Today’s 2D barcodes are incredibly efficient: small, easily, and affordably generated, and excellent at storing kilobytes of information that, in turn, can be easily decoded. But that does not mean the technology could not be improved. Using existing 2D barcode patterns, similar to the image above, researchers have developed methods for embossing the code into the surface of plastics and metals. Specialized scanners then read not just the bar/space patterns of the symbol, but also the varying heights of the bars and spaces. This allows significantly more information to be encoded into the barcode compared to a 2D barcode. This technology might seem similar to the technology of the cube but is fundamentally different in that it is much simpler to use commercially. It is not at the “invisible to the naked eye” size that the cube is and more standardized barcode readers can scan these types of barcodes. It can be used in places where you normally can’t bring a microscope, such as a busy factory, warehouse, retail operation, or outdoors.
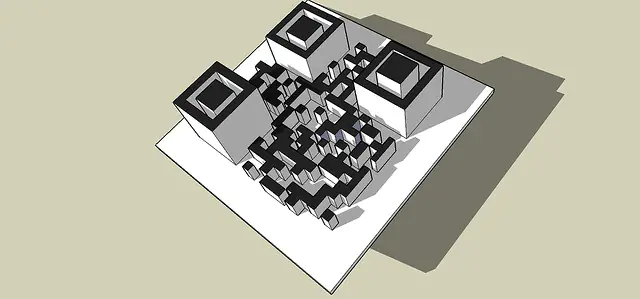
An obvious advantage this type of 3D barcode has over its 2D counterpart is it can hold more information. This is important because it allows for the size of data to not be the limiting factor. But more importantly, the primary advantage of embossed 3D barcodes is that they are physically embedded in the material and can be used in harsh environments with less worry about damage and wear.
The dominant use of this 3D barcode technology is in industry, where a traditional 1D or 2D barcode label cannot withstand high temperatures, caustic chemicals, or wear from friction. Having the manufacturing details engraved into the machinery itself would allow for easy processing of technical inspections, where the inspector would simply scan the barcode and use the information to conduct an inspection. Additionally, engraving the barcode reduces the need for high levels of error correction. Since the material the barcode is being embedded in is durable, physical damage is less likely; reducing the need for a high level of error correction and freeing up space for data instead.
There are some challenges with this technology: the scanners for these barcodes are not simply image capture devices, they are an advanced system of lasers and receivers required to detect and decode data forming from all three dimensions. Because the barcode has different heights and depths, decoding the barcode cannot simply be done by a standard smartphone camera and application, as is commonly done for 2D barcodes. This prevents this type of 3D barcode technology from being used in more diverse ways, such as by consumers in everyday use. However, it does replace standard 2D barcodes in industry, and wherever it is more useful to not have a label. Additionally, the printing/barcode generation process for embossed 3D codes is more expensive and difficult than that of standard barcode labels.
This technology is still improving, so it is possible reading such 3D barcodes will improve to the point of being able to use smartphone cameras as readers. In the future, as the processes for creating and reading the barcode improve, perhaps this 3D technology for barcodes will become the standard.
Coloring Outside the Lines
What exactly does it mean to be in 3D versus 2D (or even 1D for that matter)? The obvious answer is that you extend out into the z-axis: you become more than a flat object. This is exactly the approach the two previously discussed technologies took: the barcode data is represented in three physical dimensions.
In terms of barcode technology though, defining barcode “dimensions” strictly by their physical properties is not accurate: rather, the term dimension applies to how data is stored in the barcode. Consider the following Code 128 barcode example:

You can plainly see that the barcode is physically represented in two dimensions; it has height and width. So why then is this referred to as a one-dimensional (1D) barcode? It’s because the data is only represented in one dimension: across the “width” of the barcode. The same “data” is represented across the entire height of the barcode; visually you can see this as the black/white pattern of the code is the same from the top of the code to its bottom. It doesn't matter where a scanner reads this code: across the top, middle, or bottom; as long as the scanner can read across the width of the code, the data can be decoded. Now consider the following Data Matrix barcode:

Visually you can see that this type of barcode does not possess distinct vertical black and white lines as the Code 128 barcode did; rather, a Data Matrix barcode consists of many rows and columns of black/white squares (typically arranged as a square overall). In this case, the data in the barcode is represented in two dimensions: across its width and height. Unlike 1D barcodes though, a scanner must read the entire symbol (or virtually the entire symbol for smarter scanners) to be able to decode the message it contains.
Thus, when considering how to expand the capacity of traditional barcodes, designers looked for a third “data representation” dimension; that is, a third way of representing data; but not necessarily thinking in terms of physical dimensions. One innovative solution that quickly emerged was the use of color as the third dimension: rather than just using black and white spaces of varying widths, why not use color patterns, or even combine color patterns with varying widths? This approach has led to many creative “3D” barcode technologies.

One such solution, the High Capacity Color Barcode (HCBB) was introduced in 2007 by Microsoft. These barcodes utilized technology similar to the QR Codes we frequently utilize but have the capability to store a much larger amount of information compared to the standard black and white 2D barcodes. They achieved this high level of information density by allowing up to 8 different colors into the printing of their barcode. This allows for their scanners to interpret a much deeper level of encoding, as having 8 colors creates vastly more combinations of colors and arrangements of patterns.
This type of encoding is efficient but has its own problems. For example, the barcode scanner requires special programming and algorithms to interpret the different colors. Additionally, the colors could possibly fade if the code is outdoors due to weather, or other stressors, whereby the scanner might have difficulty interpreting the code.

In 2006, a Japanese company “Content Idea of Asia” created what they named a “Paper Memory” (PM) code. As seen above, this code holds a strong resemblance to the popular QR Code, and bases much of its technology on it, but has the obvious difference of displaying a wide variety of colors. The ability to recognize and encode in a multitude of colors allows for exponentially larger amounts of data to be encoded. For example, a standard QR Code might hold a message that redirects your phone’s browser to a website holding an image. With a PM code, you could easily encode the image or even small videos of low quality directly into the barcode.
This is obviously an amazing step in improving barcode technology but has its deficiencies as well. Like Microsoft’s “HCCB”, colors might not be effective outdoors, possibly becoming bleached or damaged. Additionally, the algorithm for reading the barcodes is very complex, making it slower, and possibly difficult for older phones, cameras, and scanners to detect. Being fast and easy to use is an important part of AIDC solutions, and PM coding technology is no exception. However, the perks of these barcodes could certainly outweigh their faults. These barcodes are small and don’t require special readers beyond a color camera, which means they can be scanned on most modern smartphones. Their ease of use and capacity make this technology appealing to companies for marketing and other such uses.
Three-dimensional barcode technology could be the future of barcode technology, but in many cases will have to adapt and improve in order for companies and the public to take an interest. The world will always value the greatest perk that 3D barcode technology currently provides: increased data storage. As the Internet continues to ingrain itself in our everyday life, being able to easily view information continues to become more essential.
Lately, some barcode scanners can do wonders with the QR and Data Matrix barcodes as shown here:


So, these too are being used within various industries, whenever a media person wants to present their products in a more interesting way.
If you missed Part 1, "The Evolution of Barcodes", or Part 2 "A New Dimension", we hope you will take the time to explore and share.
